In a previous blogpost we explained how we reduced our observability bill using Quickwit thanks to its ability to store the logs and traces using object storage:
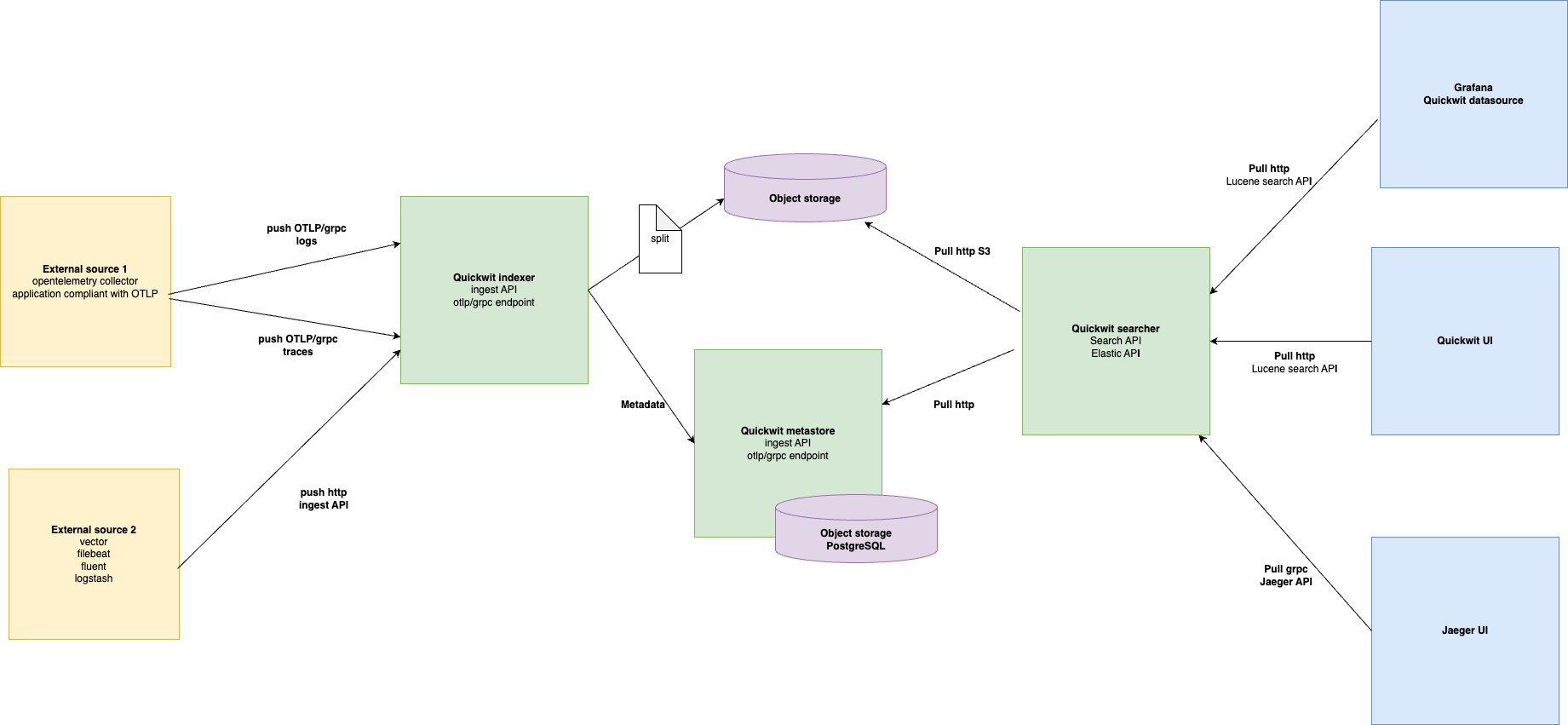
We also said that we were using VictoriaMetrics in order to store our metrics but weren't satisfied by it lacks of object storage support.
We always wanted to store all our telemetry, including the metrics, on object storage but weren't convinced by Thanos or Mimir which still rely on Prometheus to work making them very slow.
The thing is for all of cwcloud's metrics, we're using the OpenMetrics format with a /v1/metrics endpoint like most of the modern observable applications following the state of art of observability.
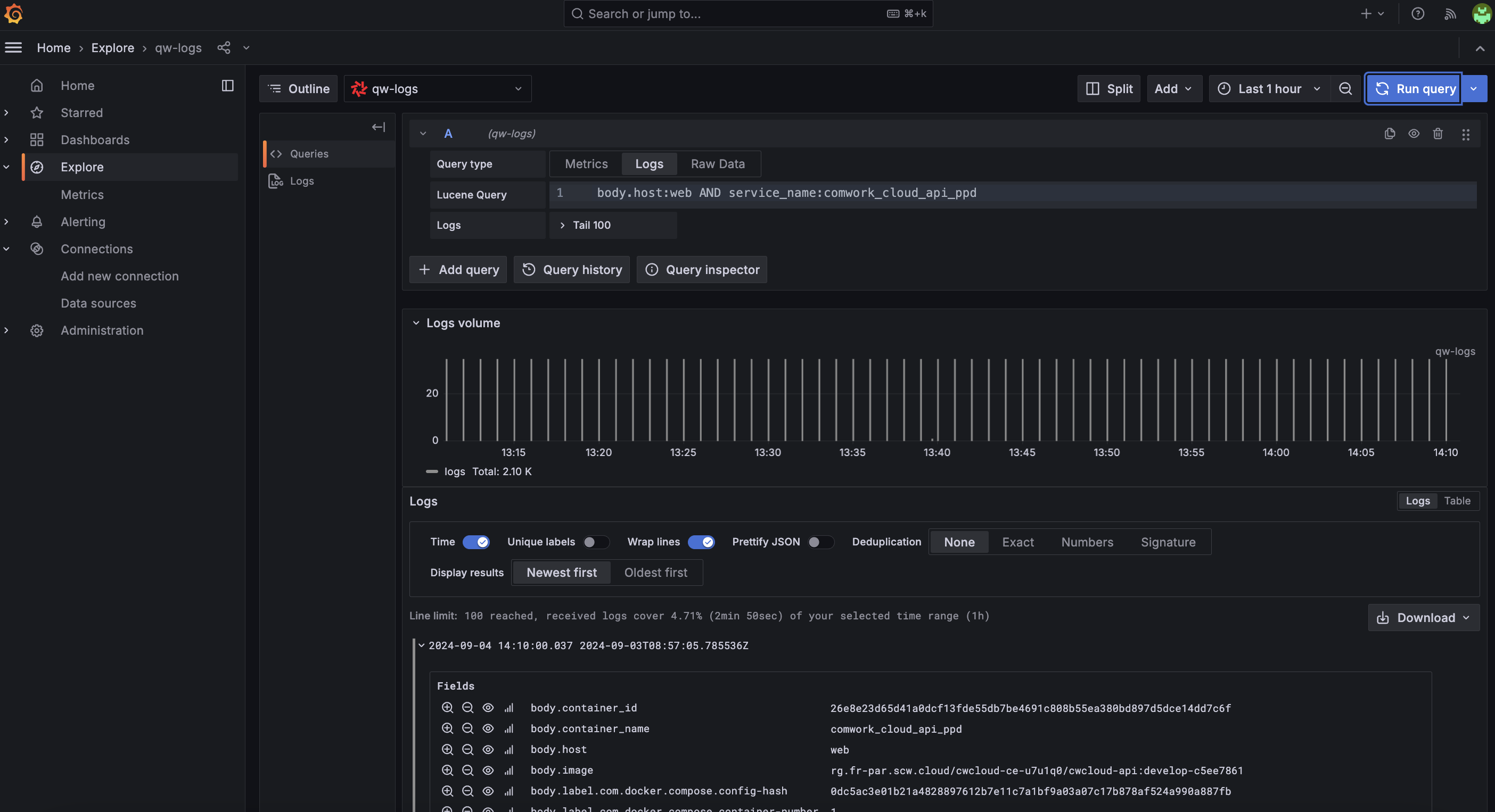
Moreover, all of our relevant metrics are gauges and counter and our need is to set Grafana dashboards and alerts which looks like this:
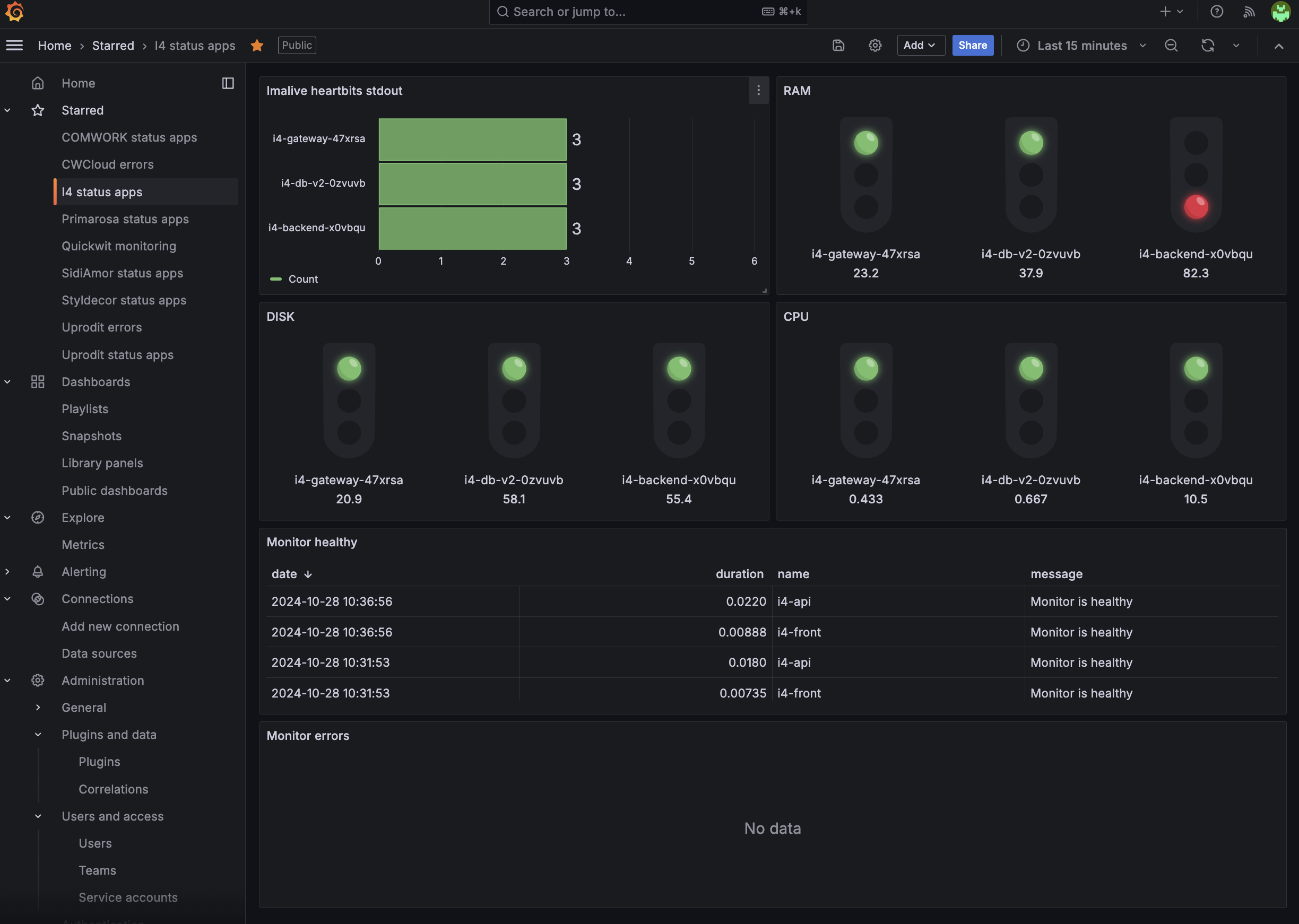
In fact, we discovered that it's perfectly perfectly feasible to setup the different threshold and do some Grafana visualizations based on simple aggregations (average, sum, min/max, percentiles) using the Quickwit's datasource:
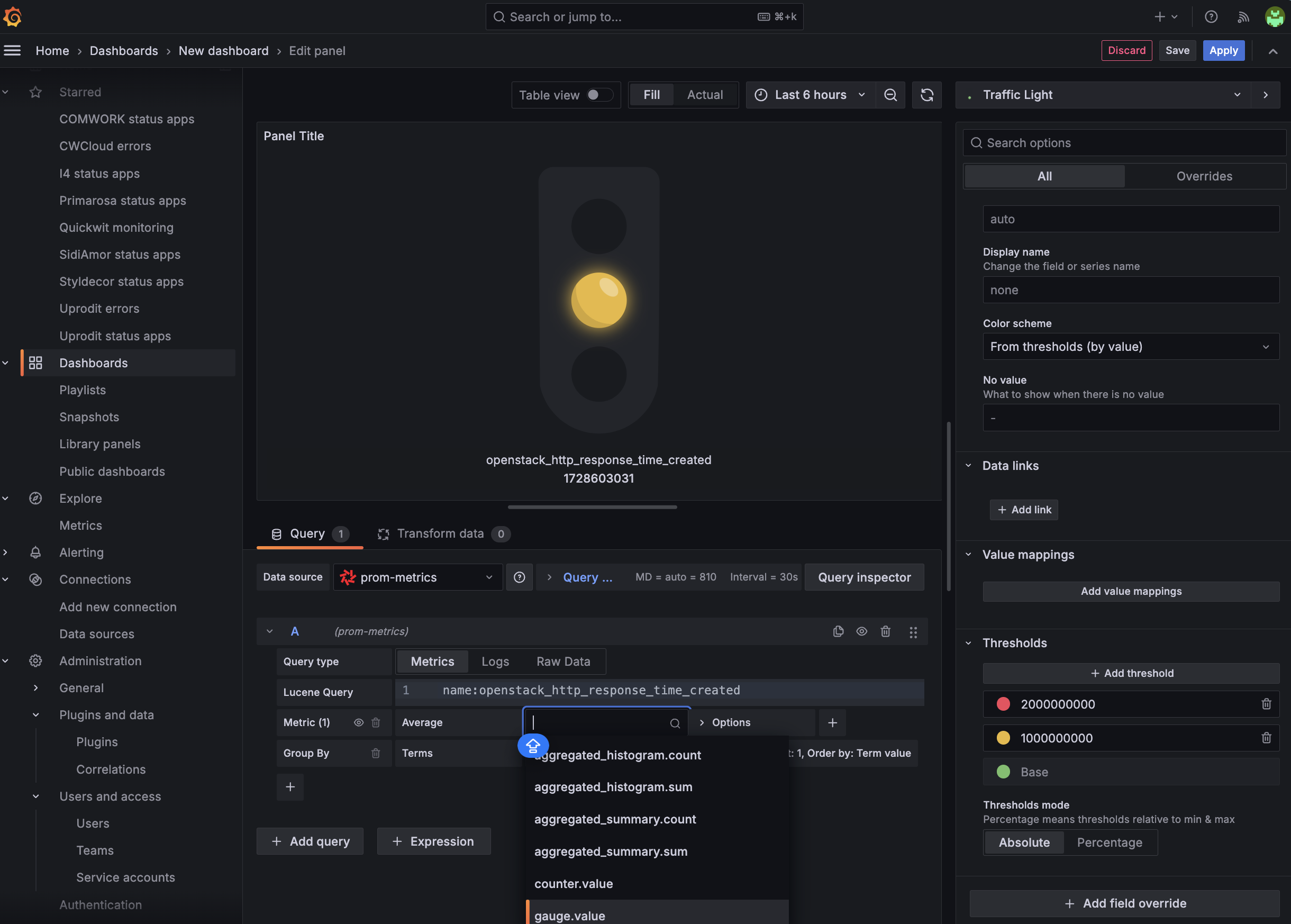
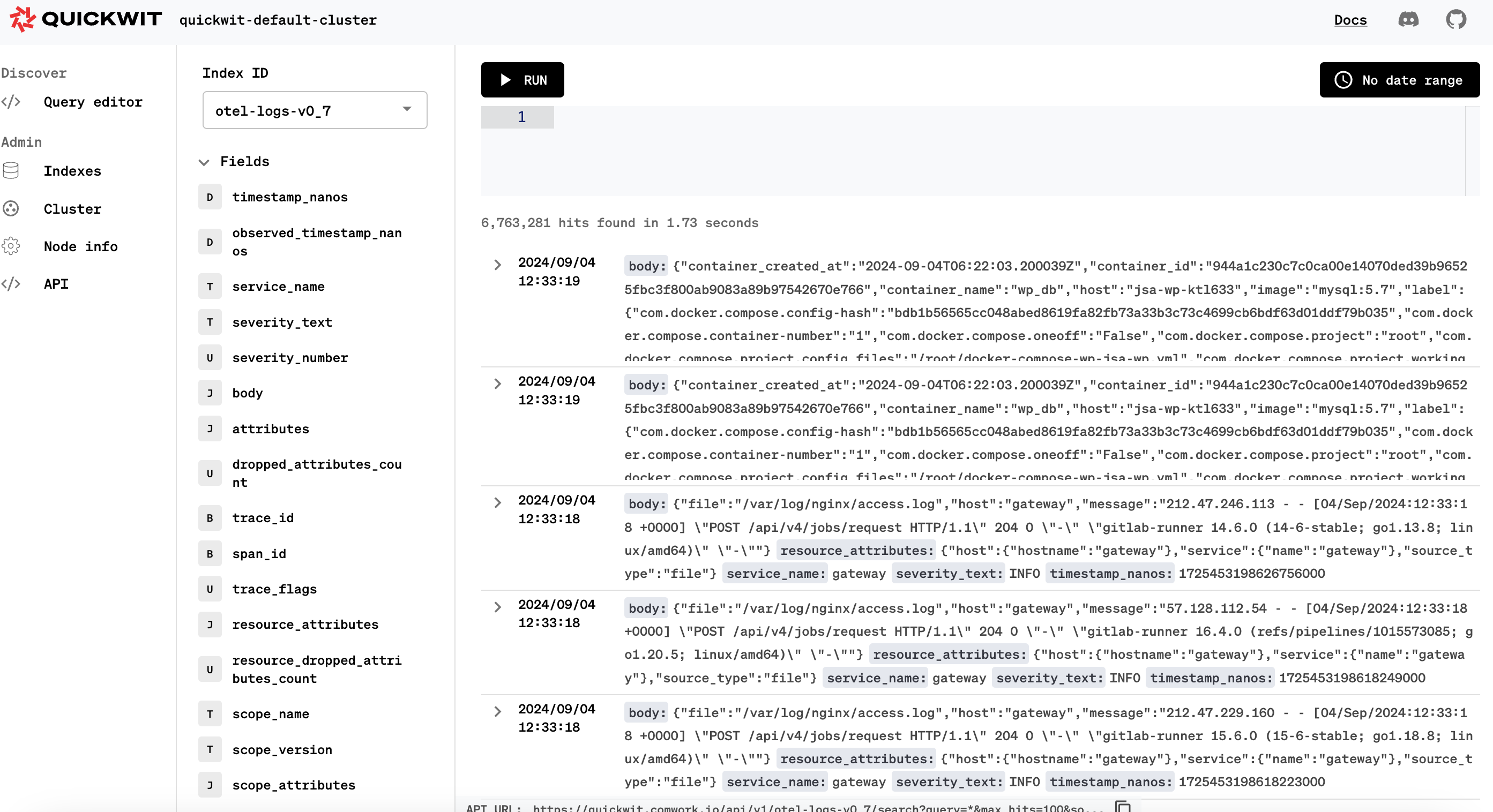
However, if you're used to also search and filter metrics using PromQL in the metrics explorer, you'll have to adapt your habits to use lucene query instead:
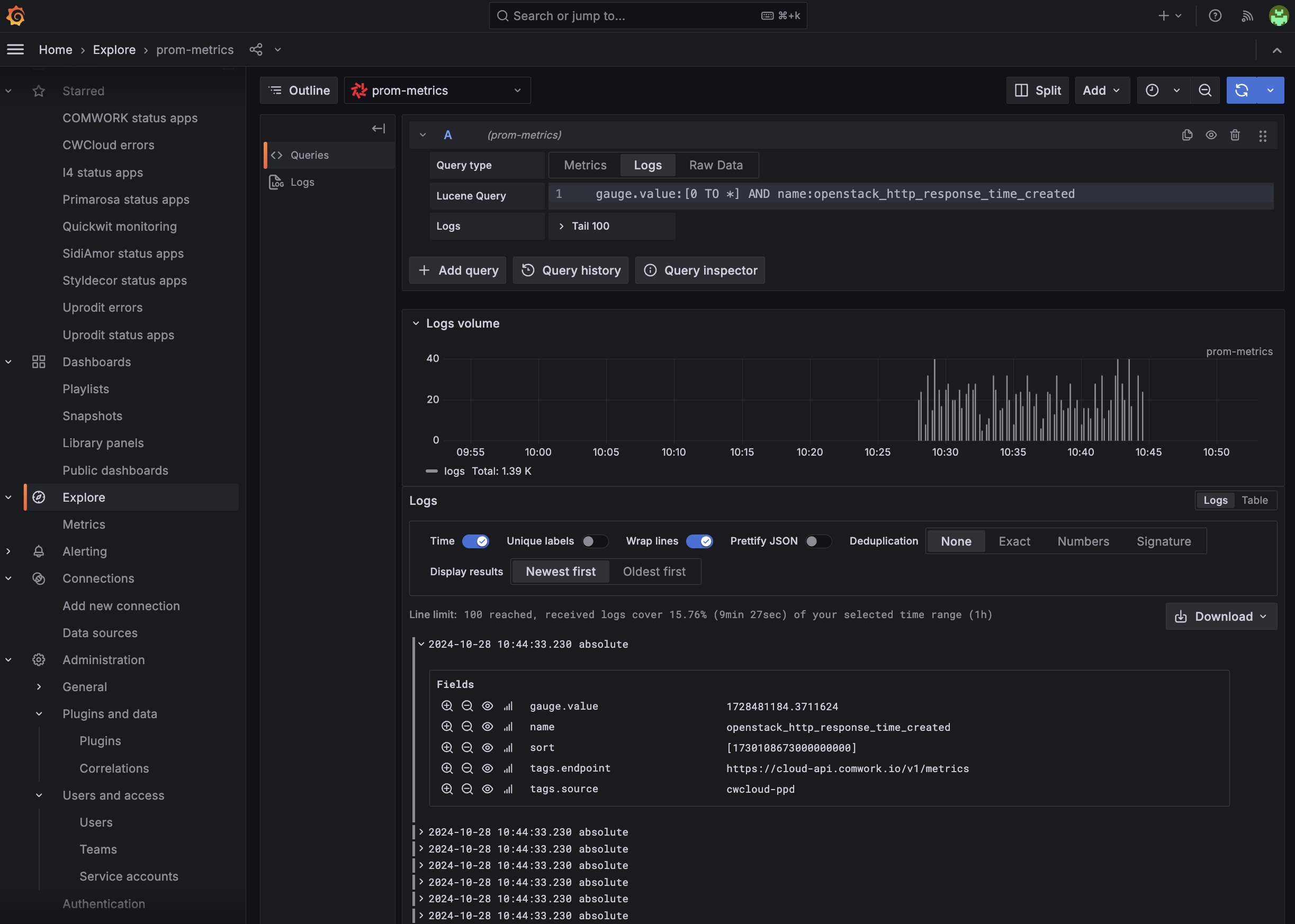
As you can see, it's not a big deal ;-p
That been said, in order to scrap and ingest the prometheus/openmetrics http endpoints, we choosed to use vector1 with this configuration:
sources:
prom_app_1:
type: "prometheus_scrape"
endpoints:
- "https://cloud-api.comwork.io/v1/metrics"
transforms:
remap_prom_app_1:
inputs: ["prom_app_1"]
type: "remap"
source: |
if is_null(.tags) {
.tags = {}
}
.tags.source = "prom_app_1"
sinks:
quickwit_app_1:
type: "http"
method: "post"
inputs: ["remap_prom_app_1"]
encoding:
codec: "json"
framing:
method: "newline_delimited"
uri: "http://quickwit-searcher.your_ns.svc.cluster.local:7280/api/v1/prom-metrics-v0.1/ingest"
Note: you cannot transform the payload structure the way you want unlike other sources like kubernetes-logs or docker_logs sources but you can add some tags to add a bit of context. That's what we did in this example adding a source field inside the tags object.
And this is the JSON mapping to be able to match with the vector output sent to the sinks and that will make you able to make aggregations on the numeric values:
{
"doc_mapping": {
"mode": "dynamic",
"field_mappings": [
{
"name": "timestamp",
"type": "datetime",
"fast": true,
"fast_precision": "seconds",
"indexed": true,
"input_formats": [
"rfc3339",
"unix_timestamp"
],
"output_format": "unix_timestamp_nanos",
"stored": true
},
{
"indexed": true,
"fast": true,
"name": "name",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "kind",
"type": "text",
"tokenizer": "raw"
},
{
"name": "tags",
"type": "json",
"fast": true,
"indexed": true,
"record": "basic",
"stored": true,
"tokenizer": "default"
},
{
"name": "gauge",
"type": "object",
"field_mappings": [
{
"name": "value",
"fast": true,
"indexed": true,
"type": "f64"
}
]
},
{
"name": "counter",
"type": "object",
"field_mappings": [
{
"name": "value",
"fast": true,
"indexed": true,
"type": "f64"
}
]
},
{
"name": "aggregated_summary",
"type": "object",
"field_mappings": [
{
"name": "sum",
"fast": true,
"indexed": true,
"type": "f64"
},
{
"name": "count",
"fast": true,
"indexed": true,
"type": "u64"
}
]
},
{
"name": "aggregated_histogram",
"type": "object",
"field_mappings": [
{
"name": "sum",
"fast": true,
"indexed": true,
"type": "f64"
},
{
"name": "count",
"fast": true,
"indexed": true,
"type": "u64"
}
]
}
],
"timestamp_field": "timestamp",
"max_num_partitions": 200,
"index_field_presence": true,
"store_source": false,
"tokenizers": []
},
"index_id": "prom-metrics-v0.1",
"search_settings": {
"default_search_fields": [
"name",
"kind"
]
},
"version": "0.8"
}
To conclude, despite the fact that Quickwit isn't a real TSDB2 (time-series database), we found it pretty easy with vector to still use it as a metrics backend with vector. And this way we still can say to our developer to rely on the OpenMetrics/Prometheus SDK to expose their metrics routes to scrap. However we're still encouraging some of our customer to use VictoriaMetrics because it's still experimental and some of them need more sophisticated computation capabilities3.
One of the improvements that we immediatly think about, would be to also implement the OpenTelemetry compatibility in order to be able to push metrics through OTLP/grpc protocol. We opened an issue to the quickwit's team to submit this idea but we think that it can be also done using vector as well.
- to get more details on the
prometheus_scrapeinput, you can rely on this documentation↩ - at the time of writing, because we know that Quickwit's team plan to provide a real TSDB engine at some point↩
- for example, using multiple metrics in one PromQL query, using the range functions such as
rateorirate...↩