Replace Google Analytics with Grafana, Quickwit and CWCloud

Hi and Merry Christmas 🎄 (again yes, I didn't thought that I was going to publish another blogpost so soon 😄).
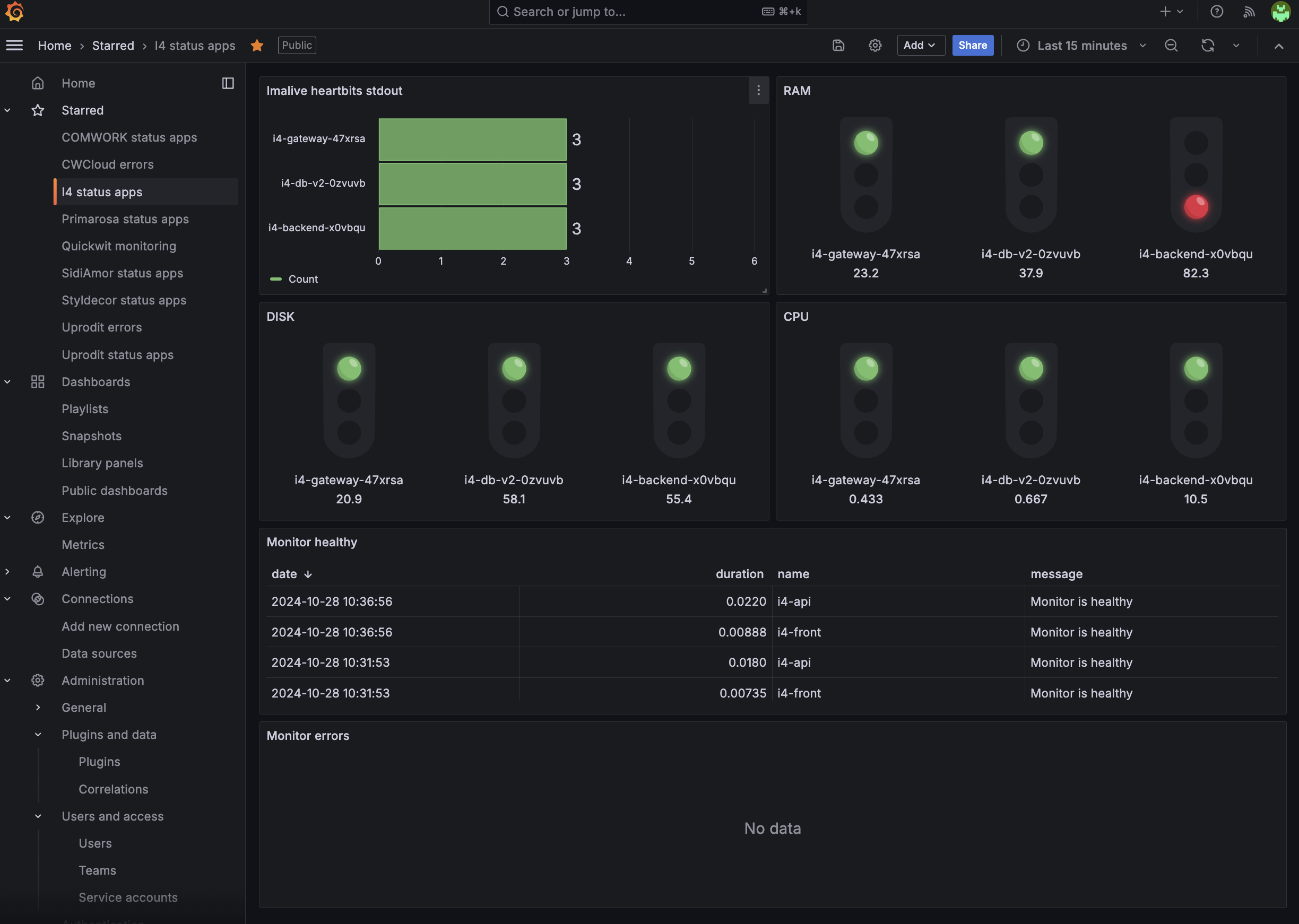
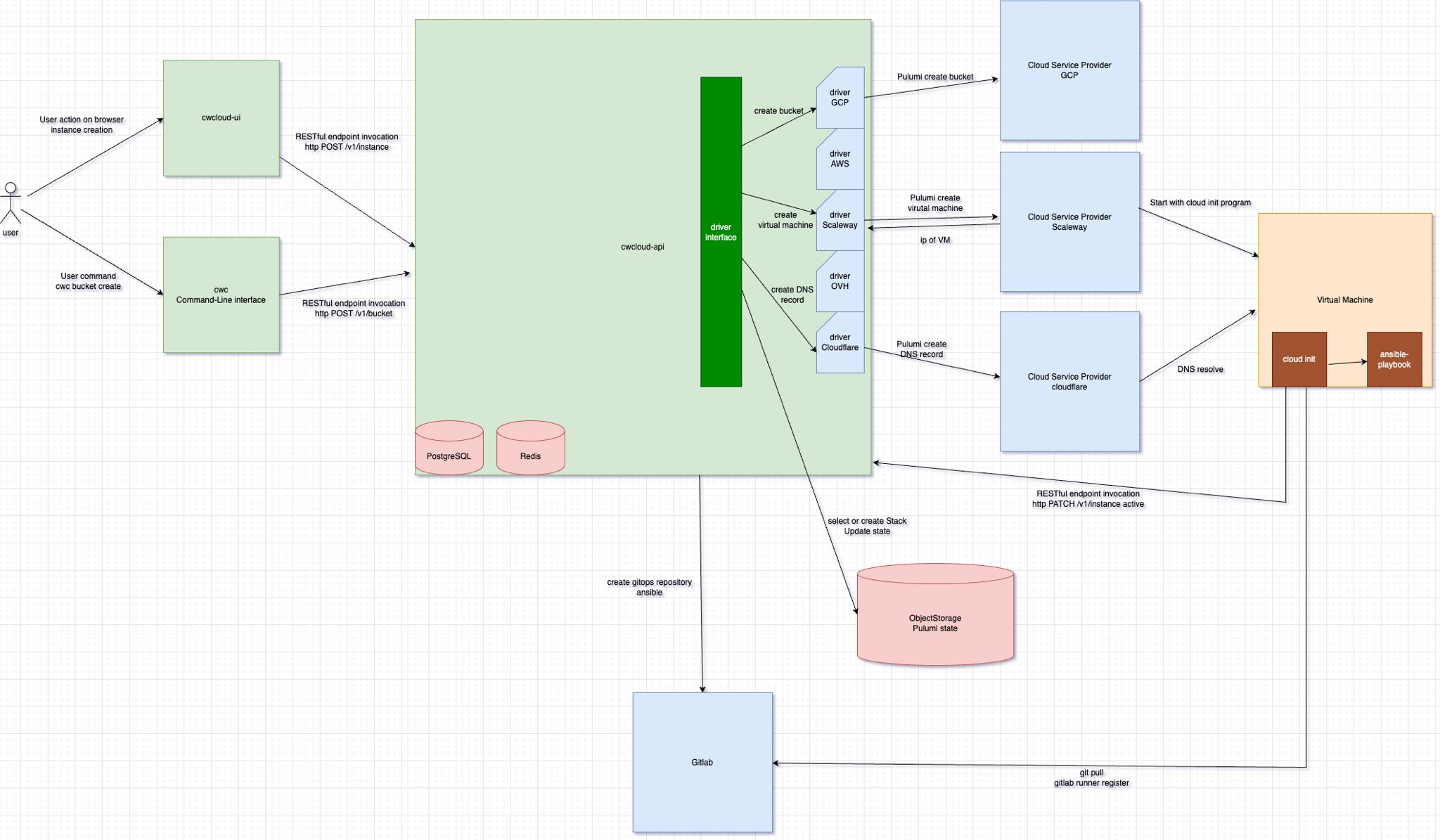
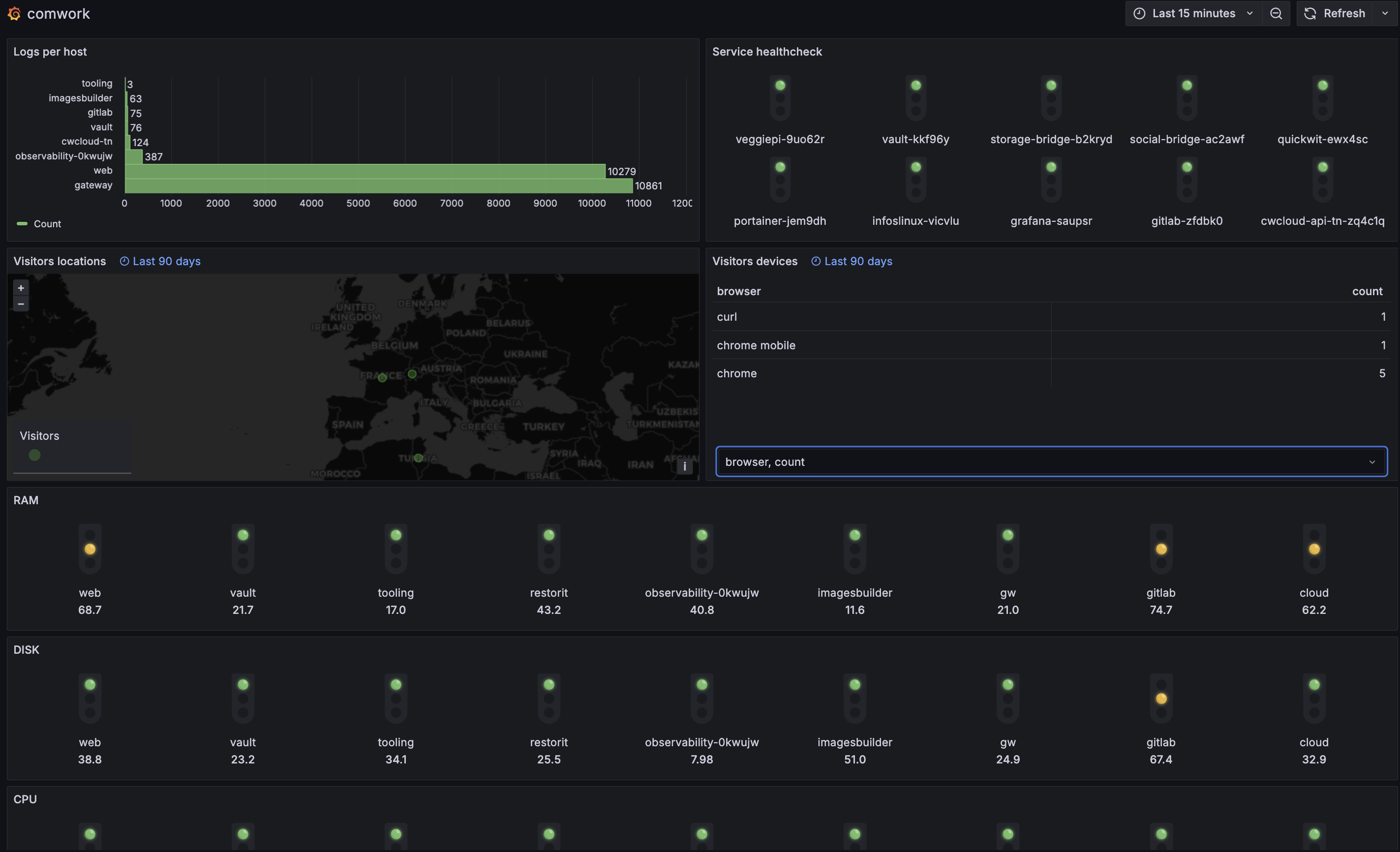
In this blogpost we'll see how to use CWCloud and Quickwit to setup beautiful dashboards like this in replacement of Google Analytics:
Before going in details, let's start to give you a bit of context of what brought us to do this transition.
First, Google Analytics ain't comply with the GDPR1. So basically it was becoming illegal to continue to use it despite it was an amazing tool to analyze our websites and application usages.
With the last case law, we started to use Matomo as a replacement and we're still providing Matomo as a Service in our CWCloud SaaS. And it worked pretty well (even if I find the UI a bit old-fashion)...
However I didn't like to maintain multiple stacks which, from my perspective, are serving the same purpose: observability. And yes web analytics should be part of it from my perspective.
I already explained why we choosed Quickwit as our observability core stack in previous blogposts:
So the idea was to use the same observability stack to track visitors data and index and display those on Grafana. And to be able to achieve this, we needed something very easy to add in our various frontend like a one-pixel image:
<img src="https://cloud-api.comwork.io/v1/tracker/img/{mywebsite}" style="display: none;"></img>
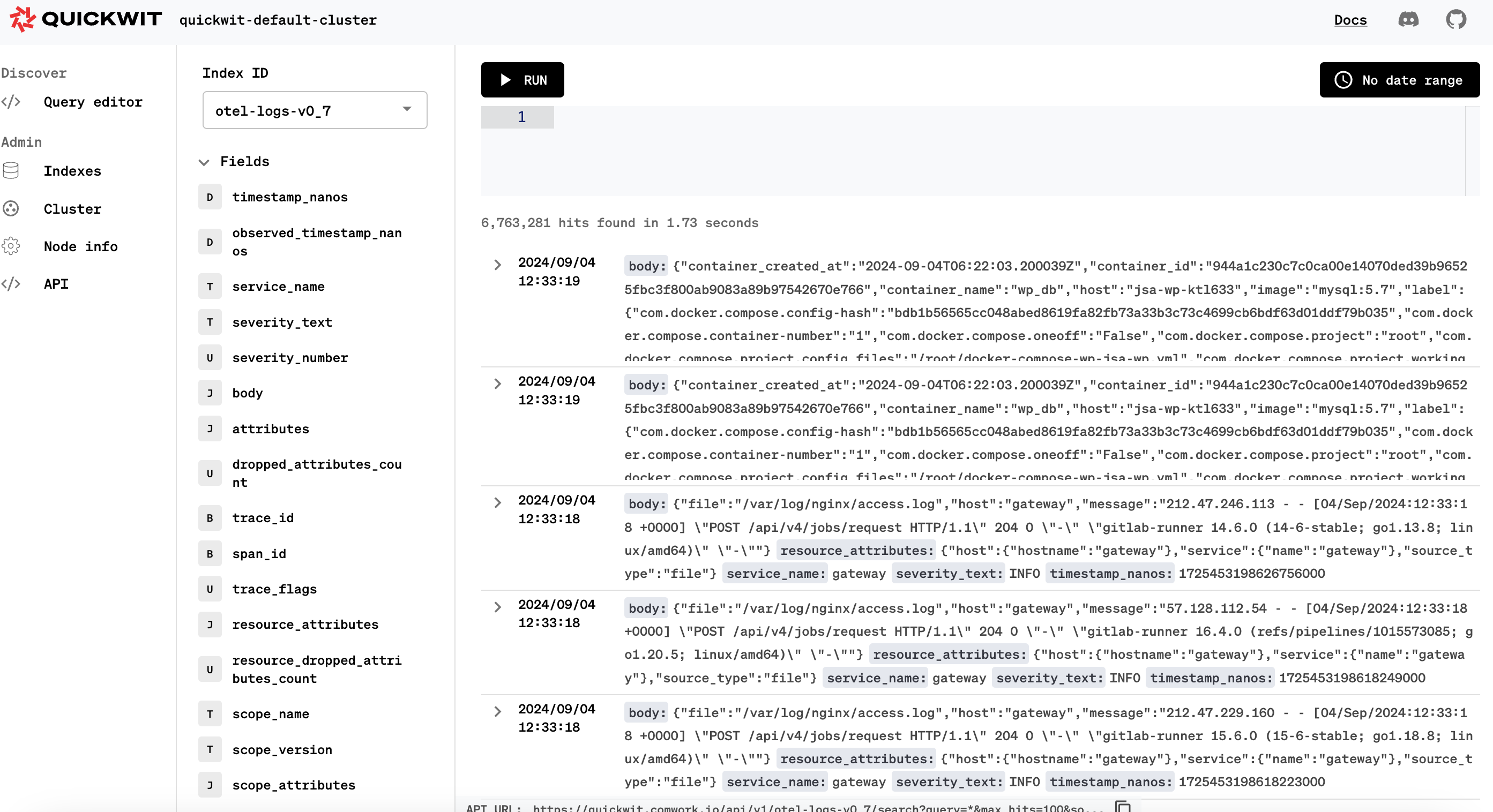
As you can see, we provided it as an endpoint in CWCloud to complete the observability features and it's documented here.
This endpoint is writing a log which looks like this:
INFO:root:{"status": "ok", "type": "tracker", "time": "2024-12-20T13:46:23.358233", "host": "82.65.240.115", "user_agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 18_1_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1.1 Mobile/15E148 Safari/604.1", "referrer": "https://cloud.comwork.io/", "website": "cloud.comwork.io", "device": "mobile", "browser": "safari", "os": "ios", "details": {"brand": "apple", "type": "iphone"}, "infos": {"status": "ok", "status_code": 200, "city": "Saint-Quentin", "region": "Hauts-de-France", "country": "France", "region_code": "HDF", "country_iso": "FR", "lookup": "FRA", "timezone": "Europe/Paris", "utc_offset": "FR", "currency": "EUR", "asn": "AS12322", "org": "Free SAS", "ip": "xx.xx.xx.xx", "network": "xx.xx.xx.0/24", "version": "IPv4", "hostname": "xx-xx-xx-xx.subs.proxad.net", "loc": "48.8534,2.3488"}, "level": "INFO", "cid": "742b7629-7a26-4bc6-bd2a-3e41bee32517"}
So at the end, it contain a JSON payload we can extract and index:
{
"status": "ok",
"type": "tracker",
"time": "2024-12-20T13:46:23.358233",
"host": "82.65.240.115",
"user_agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 18_1_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1.1 Mobile/15E148 Safari/604.1",
"referrer": "https://cloud.comwork.io/",
"website": "cloud.comwork.io",
"device": "mobile",
"browser": "safari",
"os": "ios",
"details": {
"brand": "apple",
"type": "iphone"
},
"infos": {
"status": "ok",
"status_code": 200,
"city": "Saint-Quentin",
"region": "Hauts-de-France",
"country": "France",
"region_code": "HDF",
"country_iso": "FR",
"lookup": "FRA",
"timezone": "Europe/Paris",
"utc_offset": "FR",
"currency": "EUR",
"asn": "AS12322",
"org": "Free SAS",
"ip": "xx.xx.xx.xx",
"network": "xx.xx.xx.0/24",
"version": "IPv4",
"hostname": "xx-xx-xx-xx.subs.proxad.net",
"loc": "48.8534,2.3488"
},
"level": "INFO",
"cid": "742b7629-7a26-4bc6-bd2a-3e41bee32517"
}
So let's start by creating the Quickwit mapping:
{
"doc_mapping": {
"mode": "lenient",
"field_mappings": [
{
"name": "time",
"type": "datetime",
"fast": true,
"fast_precision": "seconds",
"indexed": true,
"input_formats": [
"rfc3339",
"unix_timestamp"
],
"output_format": "unix_timestamp_nanos",
"stored": true
},
{
"indexed": true,
"fast": true,
"name": "cid",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "website",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "device",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "os",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "browser",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "host",
"type": "ip"
},
{
"indexed": true,
"fast": true,
"name": "hostname",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "user_agent",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "referrer",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "lookup",
"type": "text",
"tokenizer": "raw"
},
{
"name": "details",
"type": "object",
"field_mappings": [
{
"indexed": true,
"fast": true,
"name": "brand",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "type",
"type": "text",
"tokenizer": "raw"
}
]
},
{
"name": "infos",
"type": "object",
"field_mappings": [
{
"indexed": true,
"fast": true,
"name": "status",
"type": "text",
"tokenizer": "raw"
},
{
"name": "status_code",
"fast": true,
"indexed": true,
"type": "u64"
},
{
"indexed": true,
"fast": true,
"name": "city",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "region",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "country",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "region_code",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "country_iso",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "timezone",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "utc_offset",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "currency",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "asn",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "network",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "ip",
"type": "ip"
},
{
"indexed": true,
"fast": true,
"name": "org",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "version",
"type": "text",
"tokenizer": "raw"
},
{
"indexed": true,
"fast": true,
"name": "loc",
"type": "text",
"tokenizer": "raw"
}
]
}
],
"timestamp_field": "time",
"max_num_partitions": 200,
"index_field_presence": true,
"store_source": false,
"tokenizers": []
},
"index_id": "analytics-v0.4",
"search_settings": {
"default_search_fields": [
"website",
"cid",
"host",
"referrer",
"infos.ip",
"infos.country",
"infos.country_iso",
"infos.city",
"infos.region_code",
"infos.timezone",
"infos.currency",
"infos.version"
]
},
"version": "0.8"
}
Note: as you can see, we moved the lookup field to the root document in order to be able to use the Geomap plugin of Grafana.
Once it's done, we can use Vector, as usual, to parse this log line with the following remap function:
remap_analytics:
inputs:
- "kubernetes_logs"
type: "remap"
source: |
.time, _ = to_unix_timestamp(.timestamp, unit: "nanoseconds")
.message = string!(.message)
.message = replace(.message, r'^[^:]*:[^:]*:', "")
.body, err = parse_json(.message)
if err != null || is_null(.body) || is_null(.body.cid) || is_null(.body.type) || .body.type != "tracker" {
abort
}
.cid = .body.cid
.website = .body.website
.browser = .body.browser
.device = .body.device
.os = .body.os
.host = .body.host
.referrer = .body.referrer
.user_agent = .body.user_agent
.infos = .body.infos
.details = .body.details
if is_string(.infos.lookup) {
.lookup = del(.infos.lookup)
}
del(.timestamp)
del(.body)
del(.message)
del(.source_type)
And then the sink2:
sinks:
analytics:
type: "http"
method: "post"
inputs: ["remap_analytics"]
encoding:
codec: "json"
framing:
method: "newline_delimited"
uri: "https://xxxx:yyyyy@quickwit.yourinstance.com:443/api/v1/analytics-v0.4/ingest"
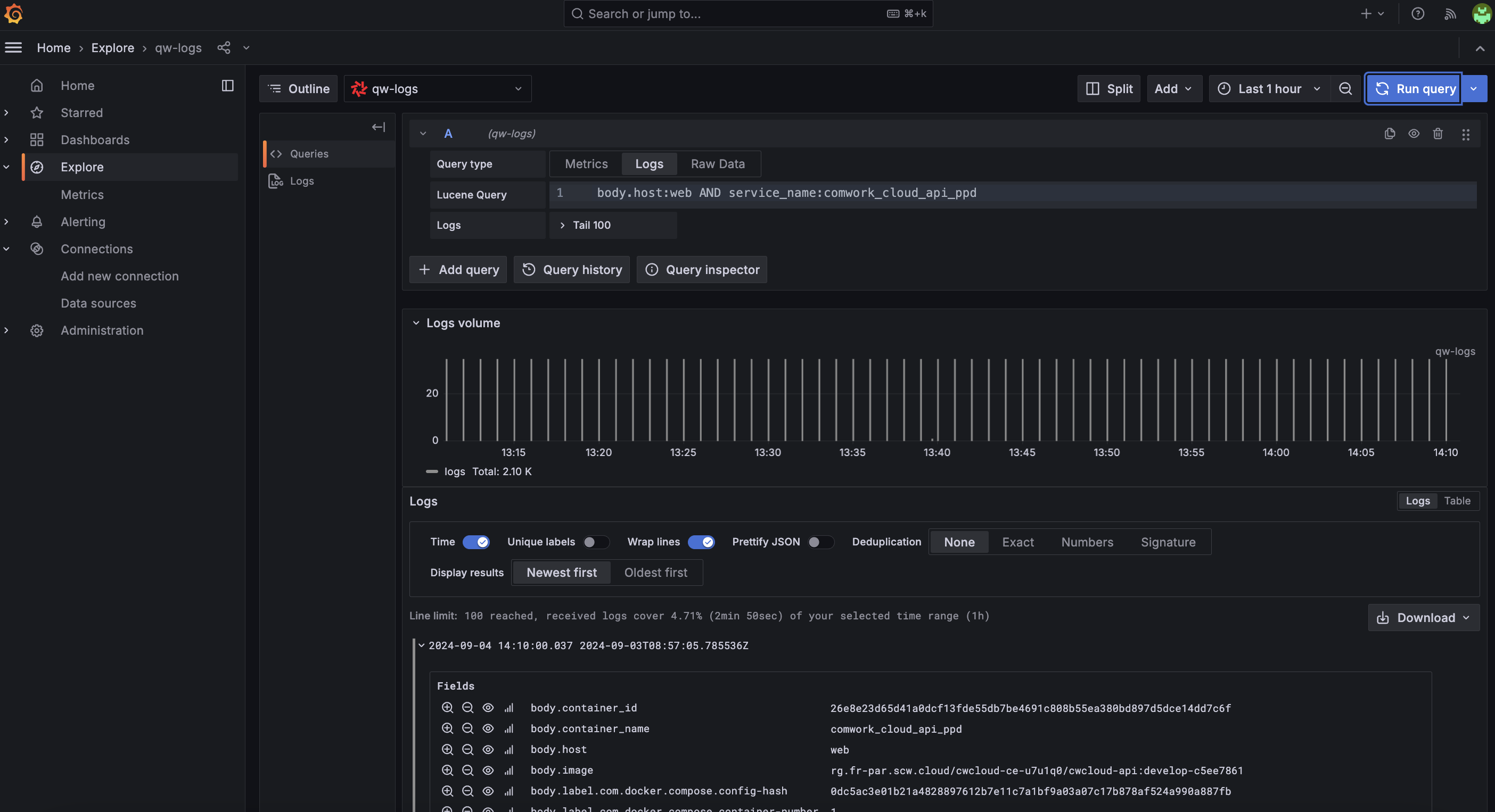
Once it's done you'll be able to do some visualization in Grafana using the Geomap plugin:
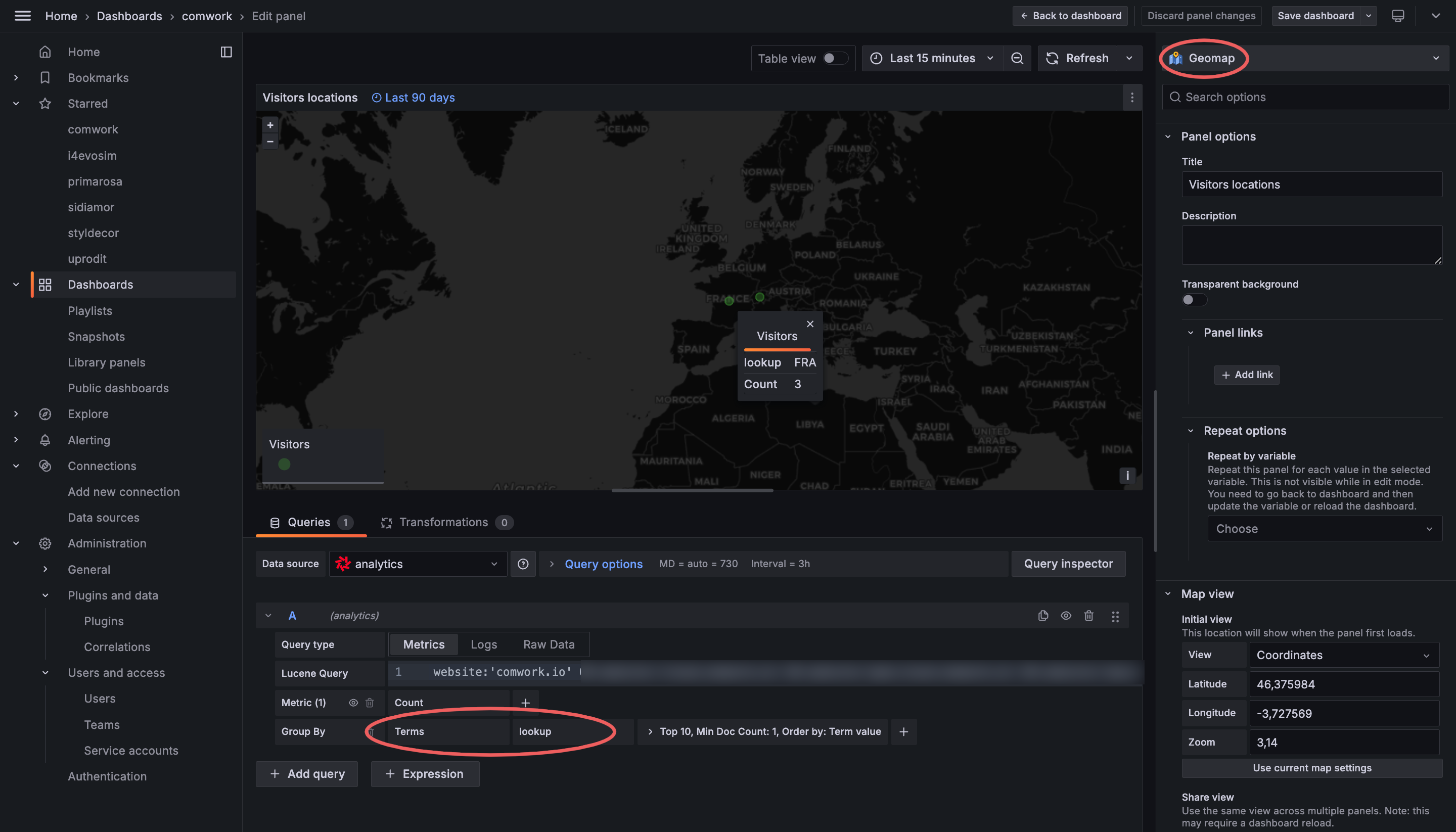
Very nice, isn't it?
Have a nice end of year and Merry Christmas 🎄 again!